



Grafická karta patrí medzi najzložitejšie hardvérové komponenty v počítači. Na prvý pohľad pôsobí len ako kovový blok s ventilátormi a čipom, no vo vnútri sa odohráva precízne riadený proces práce s dátami. Zatiaľ čo VRAM (Video RAM) uchováva obrovské objemy informácií pre hry, modely či videá, jej rýchlosť nestačí na to, aby zásobovala tisíce paralelných výpočtových jadier. Preto GPU využíva sústavu rýchlych cache, registrov a špecializovaných pamäťových vrstiev, ktoré spoločne tvoria interná pamäť GPU – dôležitý prepojovací článok medzi jadrom a hlavnou VRAM.
V predošlom článku sme sa venovali samotnej VRAM – typom pamätí ako GDDR, HBM či LPDDR. Tentoraz sa však pozrieme hlbšie – priamo do jadra GPU, kde sa rozhoduje o tom, ako rýchlo dokáže karta spracovať dáta, vykresliť obraz či vypočítať tisíce paralelných operácií. A práve interná pamäť GPU tu zohráva hlavnú úlohu.
VRAM verzus interná pamäť GPU – dva svety jednej grafiky
VRAM, teda video pamäť grafickej karty, je externá voči samotnému GPU čipu. Ukladá veľké množstvá dát – textúry, modely, frame buffery či shader programy. Ide o rýchlu pamäť, ale vzhľadom na to, že sa nachádza mimo jadra, má vyššiu latenciu než vnútorné pamäte grafickej karty. Prenos dát prebieha cez pamäťovú zbernicu (napr. 256-bit alebo 384-bit a pod.), ktorej šírka a frekvencia určujú priepustnosť.
Aj keď moderné pamäte ako GDDR6X alebo GDDR7 dosahujú ohromné rýchlosti, GPU by bolo neefektívne, keby muselo neustále siahať po dátach z VRAM. Preto sú vo vnútri čipu vybudované menšie, ale oveľa rýchlejšie pamäte, ktoré slúžia ako predĺžená ruka výpočtových jadier. Tieto komponenty spolu vytvárajú internú pamäť GPU, ktorá funguje ako inteligentný medzičlánok medzi jadrom a VRAM.
Ako funguje pamäťová architektúra GPU
Pamäťová architektúra grafickej karty funguje ako dokonale organizovaná továreň, kde každý prvok má presne určenú úlohu. VRAM predstavuje obrovský sklad – obsahuje všetky textúry, dáta, inštrukcie a modely, ktoré GPU potrebuje na výpočty. Cache pamäte fungujú ako distribučné regály, ktoré pripravujú dáta pre okamžité použitie, zatiaľ čo registre sú samotní „robotníci“, ktorí s nimi priamo pracujú. Spolu vytvárajú komplexnú sieť, v ktorej sa informácie pohybujú v presne definovaných cykloch a úrovniach rýchlosti.
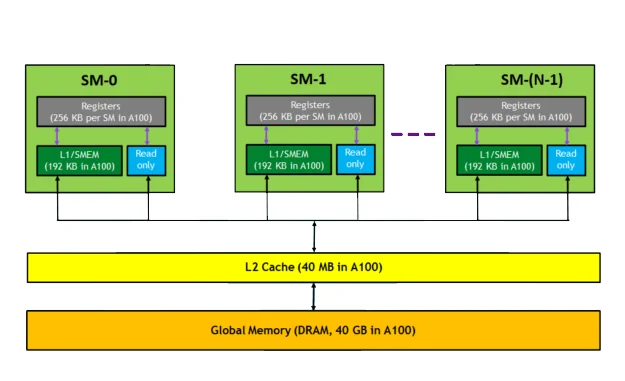
Každý výpočtový blok GPU – či už ide o streaming multiprocesor (SM) v architektúre NVIDIA alebo compute unit (CU) v architektúre AMD – má vlastné L1 cache a registre. Tieto jednotky spracúvajú stovky až tisíce vlákien paralelne, pričom každé vlákno potrebuje okamžitý prístup k svojim dátam. Aby nedochádzalo k spomaleniu, GPU neustále presúva dáta medzi cache, registrami a VRAM tak, aby boli vždy v správnom mieste v správnom čase. Tento proces riadi pamäťový radič, ktorý rozhoduje, kedy a kam sa majú informácie preniesť.
Cieľom celej architektúry je skrátiť vzdialenosť, ktorú musí informácia prejsť. Prístup do VRAM má totiž rádovo vyššiu latenciu než interné pamäte v čipe. Preto GPU ukladá najdôležitejšie dáta čo najbližšie k výpočtovým jadrom – v cache alebo registroch. Tým sa minimalizuje oneskorenie a maximalizuje počet operácií, ktoré môže karta spracovať v jednom takte.
Takto navrhnutý systém funguje v neustálom cykle: inštrukcia → načítanie dát → výpočet → uloženie výsledku → aktualizácia cache. Vďaka tomu dokážu moderné čipy spracovať miliardy inštrukcií za sekundu, pričom o plynulý tok informácií sa stará práve interná pamäť GPU, ktorá slúži ako rýchly most medzi jadrom a hlavnou VRAM.

Cache pamäte – mozog pamäťovej architektúry GPU
Základom systému, ktorý predstavuje interná pamäť GPU, sú cache vrstvy. Tie zabezpečujú, že výpočtové jadrá majú okamžitý prístup k dátam, ktoré potrebujú najčastejšie. V grafickom čipe existuje viac úrovní cache – od menších a rýchlejších až po väčšie, ktoré slúžia ako medzivrstva medzi jadrom a VRAM. Ich úlohou je neustále udržiavať dáta v pohybe tak, aby GPU nečakalo ani jediný takt.
- L1 cache sa nachádza pri výpočtových blokoch – napríklad pri shader jednotkách v architektúrach AMD alebo pri streaming multiprocesoroch (SM) v čipoch NVIDIA. Uchováva malé množstvo dát, ktoré sa spracúvajú v danom okamihu. Prístupová doba je extrémne krátka – rádovo niekoľko taktov.
- L2 cache je väčšia a zdieľaná medzi viacerými blokmi. Slúži ako centrálna výmenná zóna, kam sa ukladajú výsledky výpočtov a ku ktorým majú prístup rôzne časti GPU. Spolu s nižšími úrovňami cache vytvára základ systému, ktorý tvorí interná pamäť GPU a zabezpečuje rýchlu komunikáciu medzi jadrom a VRAM.
- Infinity Cache predstavuje najvyššiu úroveň vyrovnávacej pamäte v architektúrach AMD. Nie je to klasická L3 cache, ale funguje podobne – ako veľká medzivrstva, ktorá zvyšuje efektívnu priepustnosť pamäťového systému.
Architektúra RDNA 4 z roku 2025 používa tretiu generáciu Infinity Cache s kapacitou až 64 MB (v závislosti od modelu) a vylepšeným prepojením na L2 cache, čím zvyšuje efektívnu priepustnosť a znižuje záťaž na VRAM. Rovnaký princíp sleduje aj NVIDIA – generácia Ada Lovelace ponúka až 96 MB L2 cache v čipe AD102, zatiaľ čo novšia architektúra Blackwell ju rozširuje na až 128 MB. V oboch prípadoch ide o maximálne kapacity, ktoré sa môžu líšiť podľa konkrétneho modelu, no cieľ zostáva rovnaký – zrýchliť tok dát medzi jadrom a pamäťovým systémom a zvýšiť efektivitu, ktorú zabezpečuje interná pamäť GPU.
Registre a SRAM – rýchlosť priamo v jadre GPU
Ak sú cache pamäte mozgom grafickej karty, registre predstavujú jej reflexy. Sú umiestnené priamo vo výpočtových jednotkách a uchovávajú hodnoty, s ktorými GPU aktuálne pracuje – napríklad údaje pri výpočte svetla, tieňov či pohybu. Ich okamžitá odozva a vysoká rýchlosť patria medzi hlavné dôvody, prečo je interná pamäť GPU schopná spracúvať obrovské množstvo dát bez oneskorenia.
Každé jadro disponuje vlastným súborom registrov. Architektúra NVIDIA Ada Lovelace ich má až 65 536 na jeden multiprocesor, pričom sa dynamicky rozdeľujú medzi vlákna podľa potreby výpočtov. Podobný princíp využíva aj AMD RDNA 4, kde sa registre optimalizujú pre spracovanie inštrukcií wave32 a wave64. V kombinácii s cache vrstvami zabezpečujú maximálnu rýchlosť výpočtov a plynulú prácu celého GPU.
Špeciálne typy pamätí v rámci GPU
Okrem klasických vrstiev cache a registrov využívajú niektoré grafické procesory aj špeciálne riešenia. V mobilných GPU, napríklad v čipoch Apple A-série, ARM Mali alebo Qualcomm Adreno, sa používa architektúra Tile-Based Deferred Rendering (TBDR). GPU spracúva obraz po menších blokoch – tzv. tiles, ktoré ukladá do lokálnej tile memory. Tento prístup výrazne zvyšuje efektivitu a prispieva k tomu, že interná pamäť GPU dokáže pracovať úspornejšie a s nižšou spotrebou energie.
V integrovaných grafických riešeniach, ako sú AMD APU, Intel Arc Xe, Iris Xe alebo Apple M-série, sa zase používa zdieľaná systémová pamäť (shared memory). Ide o spoločný priestor pre CPU aj GPU, ktorý umožňuje priamy prístup k dátam bez nutnosti ich kopírovania. Hoci tento prístup šetrí energiu a zjednodušuje architektúru, nedosahuje výkon, aký ponúka dedikovaná interná pamäť GPU.
Záver
Moderné grafické karty už dávno nestavajú len na kapacite VRAM. O ich reálnom výkone rozhoduje aj vnútorná pamäťová architektúra, ktorá vďaka riešeniam, aké spája interná pamäť GPU, určuje rýchlosť spracovania dát aj celkovú efektivitu čipu. Vývoj smeruje k optimalizácii priepustnosti a inteligentnej správe dát, čo umožňuje dnešným GPU dosahovať vyšší výkon pri nižšej spotrebe. Práve táto rovnováha medzi rýchlosťou, priepustnosťou a efektivitou určuje smer, ktorým sa budú uberať budúce generácie grafických kariet.