



AMD has been building its own compute ecosystem for years to compete with the dominance of CUDA. The foundation of this strategy is AMD’s ROCm software – an open “stack” designed for parallel computing, artificial intelligence, scientific simulation and professional applications. The goal is simple: to make the computing power of AMD graphics cards available to developers without being tied to a single manufacturer’s closed platform.
AMD ROCm software links drivers, runtimes, libraries, compilers and development tools so that computations can run directly on AMD Instinct accelerators and on select Radeon graphics cards. The developer gains access to thousands of stream processors that can process large volumes of data in parallel. The platform supports open standards such as OpenMP or OpenCL, and there is a growing ecosystem around ROCm for academic, research and commercial environments.

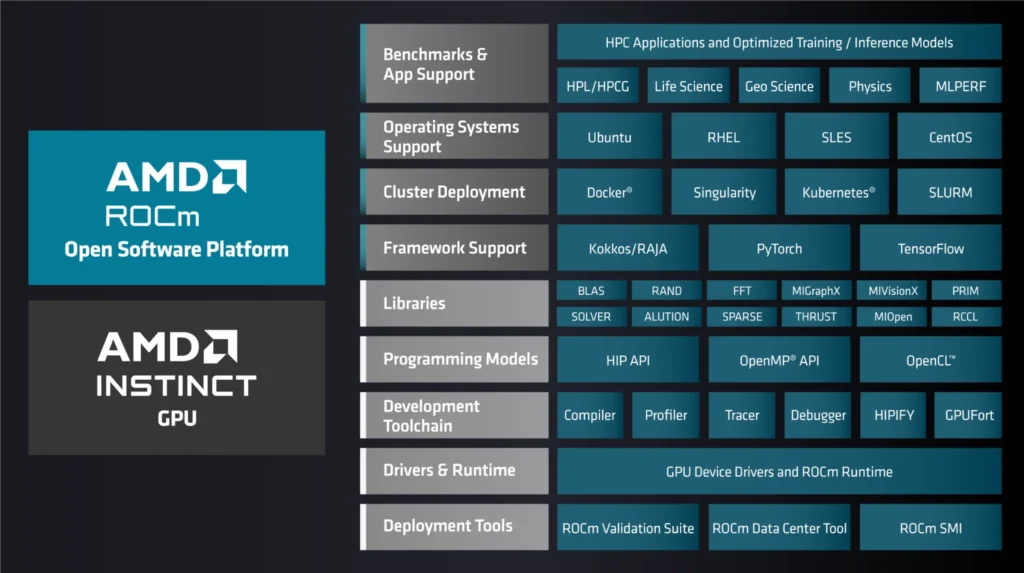
ROCm is also increasingly being integrated into popular AI frameworks. It supports PyTorch, TensorFlow, JAX and other libraries via backends optimized for Instinct accelerators. It is integration into these tools that has been a weak point for AMD for many years, but it is gradually catching up to the competition.
AMD ROCm software – the foundation of computing on AMD GPUs
AMD ROCm software forms the basic infrastructure that provides communication between the CPU and GPU. It includes drivers, LLVM-based compilers, compute libraries for BLAS, DNN or FFT, and a suite of tools for profiling, performance measurement and optimization. For HPC, libraries such as rocBLAS, rocSOLVER, MIOpen (alternative to cuDNN) or rocFFT are available. For AI developers, there are libraries optimized for matrix operations – crucial for training neural networks.
The software stack handles job scheduling, memory access, synchronization, instruction translation, and compute kernel management. The computational model is similar to CUDA – tasks are divided into smaller blocks assigned to individual Compute Units, allowing for a high degree of parallelism. Additionally, AMD ROCm software supports both “fine-grained” and “coarse-grained” memory modes, which affect how the GPU handles shared data between threads.
The advantage of ROCm is its openness. Most modules can be analyzed, optimized or integrated into custom solutions. This enables faster innovation in an academic environment where access to source code often determines the success of a scientific project.
HIP: the bridge between CUDA and the AMD world
HIP is a key element that connects ROCm to the existing CUDA ecosystem. It functions as a programming model very close to CUDA, which differs minimally. This approach allows a large portion of CUDA projects to be converted using HIPIFY tools. However, porting is not perfect – specific CUDA APIs, proprietary libraries or optimizations tied to Tensor Cores are not automatically portable.
HIP can also work as a native development model for AMD GPUs. It allows working with the same concepts – blocks, grids, threads, kernel management, synchronization or memory copying. This significantly reduces the time needed to switch between platforms. In addition, HIP maintains forward compatibility – applications written for older generations of AMD GPUs often work on newer architectures without major modifications.
With HIP, AMD can reach out to developers who have been working in a CUDA environment for years and offer them an open alternative without having to start from scratch.
Stream processors: the hardware foundation of AMD performance
Stream processors are the foundation of AMD GPU computing power. Each stream processor performs simple operations, but their real power comes from the massive parallelism of running thousands to tens of thousands of them at once.

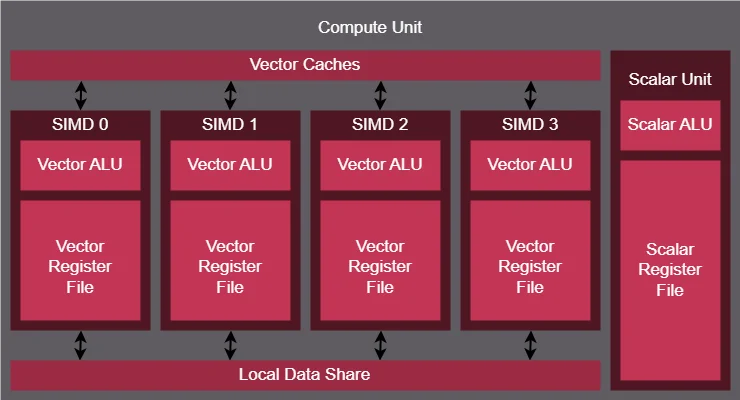
In AMD architecture, stream processors are organized in Compute Units (CUs), which include SIMD blocks, schedulers, caches, and various auxiliary units. Each CU can execute hundreds of parallel instructions in a single cycle, which is critical in AI, physics simulations, rendering, and HPC tasks.
However, RDNA and CDNA architectures work differently:
- RDNA / RDNA 2 / RDNA 3 / RDNA 4 are mainly designed for graphics tasks, but from RDNA 3 onwards they also include dedicated AI/Matrix accelerators.
- CDNA 2 and CDNA 3 are full compute architectures for HPC and AI. They include matrix cores, high-capacity memory interconnects, AI-optimized compute caches, and support for FP16, BF16, and INT8 formats.
AMD uses its own Matrix Fused Multiply-Add (MFMA) matrix operations solution in the CDNA, which serves as an equivalent to Tensor Cores, but works in a different way and in different data formats.
With these units, AMD can efficiently accelerate neural networks, large language models and massive HPC simulations.
The future of computing on AMD GPUs
AMD ROCm software is expanding with each release, and AMD is investing more and more in it. Compute libraries are faster, AI frameworks are getting stable backends for Instinct accelerators, and support for container-based deployments (Docker, Kubernetes) is easier than it used to be.
The latest MI300X and MI325X accelerators show the direction AMD is heading. High HBM capacity, extreme memory bus width, and CDNA3 compute architecture create a powerful foundation for AI supercomputing. These accelerators are already being used today by large cloud platforms to train LLM models.

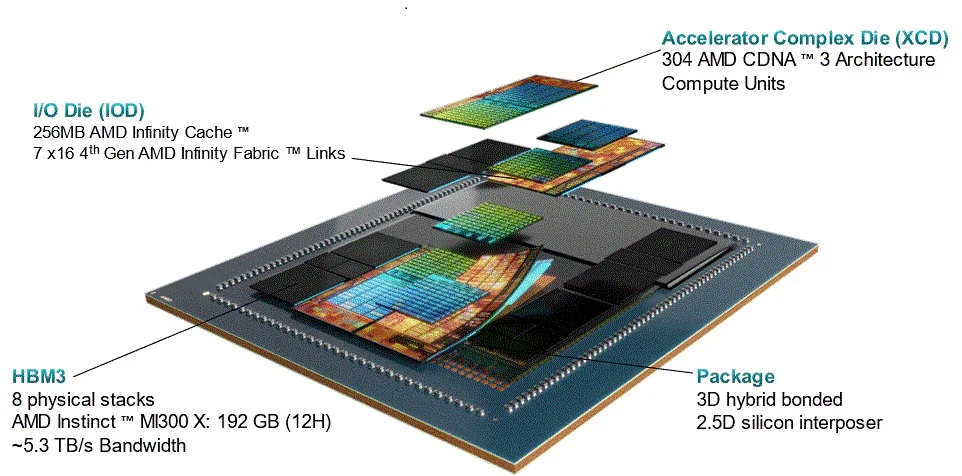
AMD ROCm software is also growing in importance as companies look for an alternative to the locked-down CUDA ecosystem. Open standards, access to source code, and broader integration options give AMD a growing advantage.
Conclusion – AMD ROCm software
AMD ROCm software and HIP form the core of the AMD computing ecosystem. ROCm provides the software infrastructure for parallel computing, HIP lowers the barriers to porting CUDA applications, and stream processors, along with RDNA and CDNA architectures, deliver high compute performance. AMD thus offers an open, flexible and fast-growing alternative in HPC, AI and professional computing.
FAQ – Frequently Asked Questions
What is AMD ROCm?
ROCm is an open software stack that allows you to run parallel computing, AI models and scientific simulations directly on AMD GPUs. It includes runtimes, compilers, libraries and development tools.
Which graphics cards does ROCm run on?
ROCm is designed primarily for AMD Instinct accelerators. It also supports selected Radeon models, but compatibility depends on the generation and specific configuration.
Is ROCm an alternative to CUDA?
Yes. ROCm is an open alternative to NVIDIA CUDA, which is mainly used in AI, HPC and servers. However, the ecosystem is not yet as large as CUDA.
What is HIP?
HIP is a programming model similar to CUDA. It allows porting part of the CUDA code to AMD GPUs and also serves as a native application development method for ROCm.


Optimize performance in AI, HPC, and creative tools. Check out great prices on AMD Radeon GPUs compatible with ROCm.