



NVIDIA CUDA is one of the most important technologies NVIDIA has brought to the world of computing. Many see it as just a tool for AI or rendering, but in reality it is a vast and sophisticated ecosystem that combines software and hardware into a single functional unit. With this combination, a graphics card can process a huge number of operations in parallel, handle computations that a traditional processor couldn’t, and deliver performance that is shaping entire industries today – from artificial intelligence, to simulation and scientific research, to professional computing software. That’s why CUDA is considered the foundation of modern GPU computing acceleration.

How NVIDIA CUDA works
NVIDIA graphics cards are designed from the ground up to handle a large number of operations at once. They contain hundreds to thousands of computing units that operate in parallel – so parallelism is a feature of the graphics cards themselves. NVIDIA CUDA technology adds a software layer to this hardware that allows developers to manage, efficiently exploit and integrate this parallelism directly into applications. Without it, the GPU would be able to run in parallel, but the software would not have as much direct access, control or optimization capabilities to the performance.
NVIDIA CUDA breaks a large computational task into many small steps. Each step is processed by a thread. Threads are joined together in groups of 32, which we call warps. The warps are organized into blocks, and the blocks make up the entire computational grid (grid). The GPU then executes these warps within Streaming Multiprocessors (SM), which are designed for massive parallelism. So CUDA doesn’t determine how much parallelism the GPU has – it determines how the software will create, lay out, and schedule these threads so that the hardware takes full advantage of its performance.
How to visualize NVIDIA CUDA in practice?
Imagine a large photograph in which you want to adjust the brightness of each pixel. The processor would change them sequentially, pixel by pixel, which is slow because it works sequentially. A graphics card does it differently: it divides the image into thousands of small tasks and assigns a separate thread to each pixel. CUDA ensures that these threads are grouped into warps, assigned to the right compute units, and have fast access to memory. The entire process is done automatically and in parallel, so the GPU adjusts all the pixels at once without the software having to deal with any of the technical details.
The software part of NVIDIA CUDA
The software portion of NVIDIA CUDA technology is the layer that allows applications to take advantage of the parallelism of the GPU without working with low-level hardware. It defines how tasks are divided into threads, warps, and blocks, and manages computation scheduling, thread synchronization, code translation, and communication between the CPU and GPU. This allows the GPU to efficiently perform computations without the developer having to manually troubleshoot the operation of the graphics card architecture.
This technology is underpinned by the CUDA Toolkit, which provides all the tools needed to create and optimize programs. The NVCC compiler translates the code into the PTX intermediate language, which increases compatibility across GPU generations. When executed, PTX is automatically translated into architecture-specific machine code, so the same program can run on new graphics without major modifications. The CUDA Toolkit includes:
- NVCC compiler – translation of CUDA code into PTX and then into GPU machine code
- CUDA Runtime API – memory management, kernel execution, CPU ↔ GPU communication
- CUDA Driver API – low-level access and detailed control over the GPU
- PTX – an intermediate language that guarantees backward compatibility across generations
- Nsight tools – tuning, performance profiling, GPU code optimization
- Optimized NVIDIA libraries – cuDNN, cuBLAS, cuFFT, Thrust, etc:
When the software prepares the calculations, CUDA breaks them down into the individual compute units of the graphics card – from CUDA Cores and Tensor Cores to registers and memory levels. The developer thus doesn’t have to deal with schedulers, caches, memory transfers or architecture details. CUDA takes these steps and provides a unified interface that enables GPUs to accelerate machine learning, simulations, physics models or rendering without complex hardware work.
The hardware part of NVIDIA CUDA
The hardware portion of NVIDIA CUDA technology includes the physical elements of the graphics card that perform parallel computation. At the core are Streaming Multiprocessors (SMs) – blocks containing registers, L1/shared memory, warp schedulers, and compute units. In each SM there are CUDA cores for general-purpose operations and Tensor Cores designed for fast matrix and AI computations. SMs can process multiple warps at once, creating the high parallelism typical of modern GPUs.
Memory architecture also plays a key role. Threads use fast registers, blocks share L1/shared memory, and all SMs use a common L2 cache as an intermediate layer between compute units and the GPU’s global memory. While VRAM itself is not directly part of the internal CUDA architecture, it does affect bandwidth and overall performance.
These components work together to enable the GPU to efficiently perform CUDA-defined computations – SMs process warps in 32-thread bursts, registers provide immediate access to data, and Tensor Cores accelerate specialized computations. The result is an architecture designed to process large amounts of data in parallel, which is critical in AI, rendering, simulation and professional computing software.

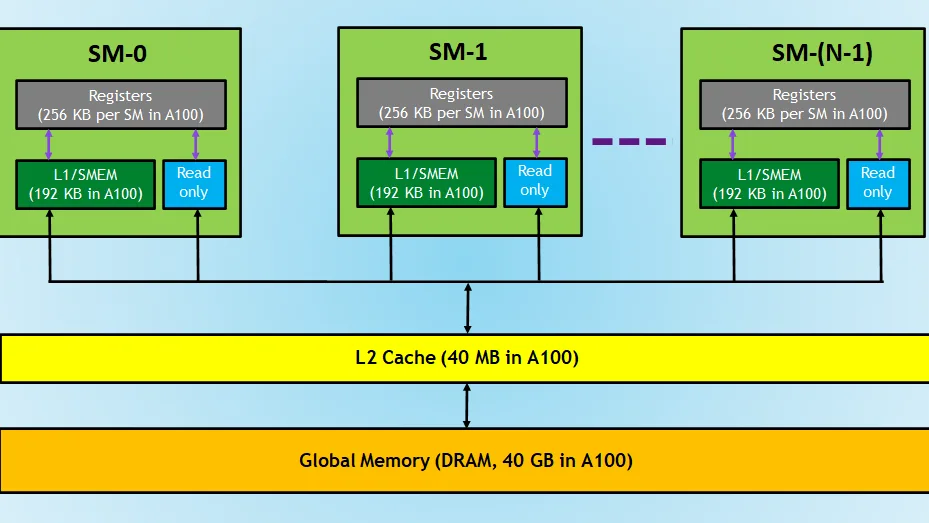
This image shows how individual Streaming Multiprocessors (SMs) interact with the memory tiers of the GPU. Each SM has registers and L1/shared memory that serve as the fastest data source for threads. Above these is a common L2 cache used by all SMs, which speeds up access to global memory (VRAM).
This hierarchy allows the GPU to efficiently parallelize tasks, minimize downtime, and ensure that each thread is working with data as fast as possible. CUDA helps direct which data to use in the SM’s fast memory and which to keep in global memory to make the computation as efficient as possible.
Ampere, Ada, Hopper and Blackwell architectures
NVIDIA CUDA technology runs on multiple generations of GPU architectures, each of which has pushed performance further. Ampere has accelerated both FP32 and tensor computations, Ada Lovelace has brought better efficiency and performance for both games and content creation, and Hopper has significantly accelerated AI computations with the new Transformer Engine. The latest Blackwell architecture takes AI performance even further – bringing 5th generation Tensor Cores, support for FP4/FP8 formats, and optimizations for large language models. Stability across all generations is provided by PTX, allowing the same CUDA code to run on new GPUs without rewriting it.
Conclusion
CUDA pushes performance further because it seamlessly integrates software and hardware into a single optimized unit that can process a huge number of parallel tasks faster than traditional CPUs. This ecosystem enables GPUs to efficiently accelerate AI, simulation, rendering, and scientific computing while remaining stable thanks to a unified programming model and compatibility across generations. Even with the advent of the Blackwell architecture, CUDA remains a key NVIDIA technology – and the foundation of computing power that underpins today’s and tomorrow’s era of acceleration.
FAQ – Frequently Asked Questions
What exactly does NVIDIA CUDA technology do?
CUDA enables GPUs to process thousands to millions of parallel operations simultaneously. This will speed up AI computations, rendering, simulations and scientific models over traditional CPUs.
Why does CUDA only work on NVIDIA graphics cards?
CUDA is a closed ecosystem developed exclusively for NVIDIA GPUs. The company keeps it stable and optimized to precisely fit their architectures and hardware.
What is the difference between CUDA Cores and Tensor Cores?
CUDA cores address general-purpose parallel computing. Tensor Cores are specialized units for AI, matrices and neural networks and bring tremendous speedups to training models.


The best performance for gaming, rendering, and professional workloads comes from GeForce RTX 50 Series graphics cards and NVIDIA’s professional models.