



NVIDIA CUDA je jednou z nejdůležitějších technologií, které NVIDIA přinesla do světa počítačů. Mnozí ji považují pouze za nástroj pro umělou inteligenci nebo vykreslování, ale ve skutečnosti se jedná o rozsáhlý a propracovaný ekosystém, který spojuje software a hardware do jednoho funkčního celku. Díky této kombinaci může grafická karta paralelně zpracovávat obrovské množství operací, zvládat výpočty, které by tradiční procesor nezvládl, a poskytovat výkon, který dnes formuje celá odvětví – od umělé inteligence přes simulace a vědecký výzkum až po profesionální výpočetní software. Proto je CUDA považována za základ moderní akcelerace výpočtů na GPU.

Jak NVIDIA CUDA funguje
Grafické karty NVIDIA jsou od základu navrženy tak, aby zvládaly velké množství operací najednou. Obsahují stovky až tisíce výpočetních jednotek, které pracují paralelně – paralelismus je tedy vlastností samotných grafických karet. Technologie NVIDIA CUDA přidává k tomuto hardwaru softwarovou vrstvu, která vývojářům umožňuje tento paralelismus spravovat, efektivně využívat a integrovat přímo do aplikací. Bez ní by sice grafický procesor mohl pracovat paralelně, ale software by neměl takový přímý přístup k výkonu, možnost jeho řízení a optimalizace.
NVIDIA CUDA rozděluje velkou výpočetní úlohu na mnoho malých kroků. Každý krok zpracovává jedno vlákno. Vlákna se spojují do skupin po 32, které nazýváme warpy. Warpy jsou uspořádány do bloků a bloky tvoří celou výpočetní síť (grid). GPU pak tyto warpy provádí v rámci streamovacích multiprocesorů (SM), které jsou navrženy pro masivní paralelismus. CUDA tedy neurčuje, jak velký paralelismus GPU má – určuje, jak software vytvoří, rozloží a naplánuje tato vlákna tak, aby hardware plně využil svůj výkon.
Jak si NVIDIA CUDA představit v praxi?
Představte si velkou fotografii, na které chcete upravit jas jednotlivých pixelů. Procesor by je měnil postupně, pixel po pixelu, což je pomalé, protože pracuje sekvenčně. Grafická karta to dělá jinak: rozdělí obraz na tisíce malých úloh a každému pixelu přiřadí samostatné vlákno. CUDA zajišťuje, aby tato vlákna byla seskupena do osnov, přiřazena správným výpočetním jednotkám a měla rychlý přístup do paměti. Celý proces probíhá automaticky a paralelně, takže GPU upravuje všechny pixely najednou, aniž by se software musel zabývat jakýmikoli technickými detaily.
Softwarová část NVIDIA CUDA
Softwarová část technologie NVIDIA CUDA je vrstva, která umožňuje aplikacím využívat paralelismus GPU, aniž by musely pracovat s nízkoúrovňovým hardwarem. Definuje, jak jsou úlohy rozděleny do vláken, warpů a bloků, a řídí plánování výpočtů, synchronizaci vláken, překlad kódu a komunikaci mezi CPU a GPU. To umožňuje GPU efektivně provádět výpočty, aniž by vývojář musel ručně řešit problémy s fungováním architektury grafické karty.
Základem této technologie je sada nástrojů CUDA, která poskytuje všechny nástroje potřebné k vytváření a optimalizaci programů. Překladač NVCC překládá kód do mezijazyka PTX, což zvyšuje kompatibilitu napříč generacemi GPU. Při spuštění je PTX automaticky přeložen do strojového kódu specifického pro danou architekturu, takže stejný program může běžet na nové grafice bez větších úprav. Sada CUDA Toolkit obsahuje:
- NVCC kompilátor – překlad kódu CUDA do PTX a poté do strojového kódu GPU
- CUDA Runtime API – správa paměti, provádění jádra, komunikace CPU ↔ GPU
- CUDA Driver API – nízkoúrovňový přístup a podrobné řízení GPU
- PTX – zprostředkující jazyk, který zaručuje zpětnou kompatibilitu napříč generacemi
- Nástroje Nsight – ladění, profilování výkonu, optimalizace kódu GPU
- Optimalizované knihovny NVIDIA – cuDNN, cuBLAS, cuFFT, Thrust atd:
Při přípravě výpočtů software CUDA rozděluje výpočty na jednotlivé výpočetní jednotky grafické karty – od CUDA Cores a Tensor Cores až po registry a úrovně paměti. Vývojář se tak nemusí zabývat plánovači, cache, přenosy paměti ani detaily architektury. CUDA tyto kroky přebírá a poskytuje jednotné rozhraní, které umožňuje GPU akcelerovat strojové učení, simulace, fyzikální modely nebo vykreslování bez složité práce s hardwarem.
Hardwarová část NVIDIA CUDA
Hardwarová část technologie NVIDIA CUDA zahrnuje fyzické prvky grafické karty, které provádějí paralelní výpočty. Jádrem jsou streamovací multiprocesory (SM) – bloky obsahující registry, sdílenou paměť L1, plánovače warp a výpočetní jednotky. V každém SM jsou jádra CUDA pro univerzální operace a jádra Tensor určená pro rychlé maticové výpočty a výpočty umělé inteligence. Jednotky SM mohou zpracovávat více warpů najednou, což vytváří vysoký paralelismus typický pro moderní GPU.
Klíčovou roli hraje také architektura paměti. Vlákna používají rychlé registry, bloky sdílejí paměť L1/shared memory a všechna SM používají společnou mezipaměť L2 jako mezivrstvu mezi výpočetními jednotkami a globální pamětí GPU. Samotná paměť VRAM sice není přímou součástí vnitřní architektury CUDA, ale ovlivňuje šířku pásma a celkový výkon.
Tyto komponenty spolupracují, aby GPU mohl efektivně provádět výpočty definované v CUDA – SM zpracovávají osnovačky v 32vláknových sériích, registry poskytují okamžitý přístup k datům a Tensor Cores urychlují specializované výpočty. Výsledkem je architektura navržená pro paralelní zpracování velkého množství dat, což je rozhodující pro umělou inteligenci, vykreslování, simulace a profesionální výpočetní software.

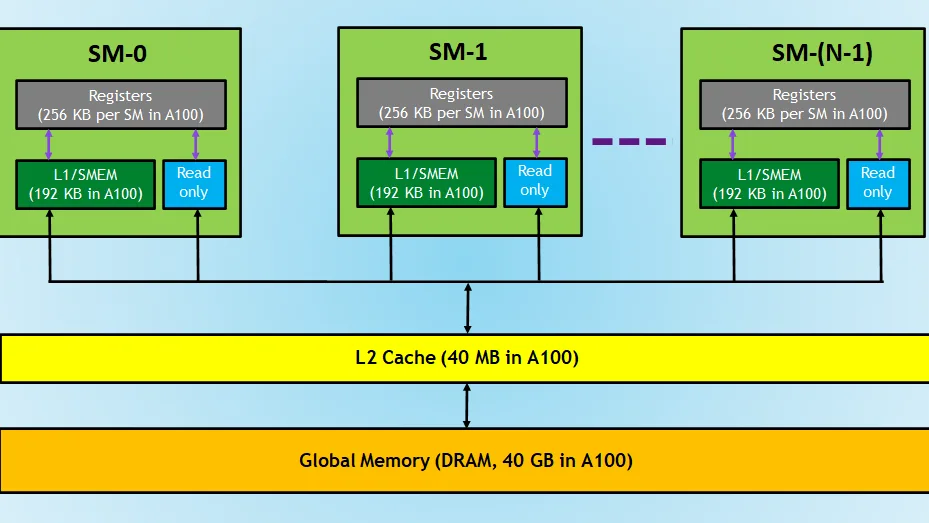
Tento obrázek ukazuje, jak jednotlivé streamovací multiprocesory (SM) spolupracují s paměťovými vrstvami GPU. Každý SM má registry a sdílenou paměť L1, které slouží jako nejrychlejší zdroj dat pro vlákna. Nad nimi se nachází společná mezipaměť L2, kterou používají všechny SM a která urychluje přístup ke globální paměti (VRAM).
Tato hierarchie umožňuje GPU efektivně paralelizovat úlohy, minimalizovat prostoje a zajistit, aby každé vlákno pracovalo s daty co nejrychleji. CUDA pomáhá řídit, která data mají být použita v rychlé paměti SM a která v globální paměti, aby byl výpočet co nejefektivnější.
Architektury Ampere, Ada, Hopper a Blackwell
Technologie NVIDIA CUDA pracuje na několika generacích architektur GPU, z nichž každá posunula výkon dál. Ampere zrychlila výpočty FP32 i tenzorů, Ada Lovelace přinesla vyšší efektivitu a výkon pro hry i tvorbu obsahu a Hopper výrazně zrychlil výpočty umělé inteligence díky novému Transformer Engine. Nejnovější architektura Blackwell posouvá výkon AI ještě dál – přináší tensorová jádra 5. generace, podporu formátů FP4/FP8 a optimalizace pro velké jazykové modely. Stabilitu napříč všemi generacemi zajišťuje technologie PTX, která umožňuje spouštět stejný kód CUDA na nových GPU bez nutnosti jeho přepisování.
Závěr
CUDA posouvá výkon dál, protože plynule integruje software a hardware do jediné optimalizované jednotky, která dokáže zpracovávat obrovské množství paralelních úloh rychleji než tradiční CPU. Tento ekosystém umožňuje GPU efektivně urychlovat umělou inteligenci, simulace, vykreslování a vědecké výpočty, přičemž zůstává stabilní díky jednotnému programovacímu modelu a kompatibilitě napříč generacemi. I po příchodu architektury Blackwell zůstává CUDA klíčovou technologií společnosti NVIDIA – a základem výpočetního výkonu, který je základem dnešní i budoucí éry akcelerace.
Často kladené otázky – Často kladené otázky
Co přesně dělá technologie NVIDIA CUDA?
CUDA umožňuje GPU zpracovávat tisíce až miliony paralelních operací současně. To urychlí výpočty umělé inteligence, vykreslování, simulace a vědecké modely oproti tradičním CPU.
Proč CUDA funguje pouze na grafických kartách NVIDIA?
CUDA je uzavřený ekosystém vyvinutý výhradně pro grafické procesory NVIDIA. Společnost jej udržuje stabilní a optimalizovaný přesně na míru svým architekturám a hardwaru.
Jaký je rozdíl mezi jádry CUDA a Tensor Cores?
Jádra CUDA se zabývají paralelními výpočty pro obecné účely. Tensor Cores jsou specializované jednotky pro umělou inteligenci, matice a neuronové sítě a přinášejí obrovské zrychlení tréninkových modelů.


Nejlepší výkon pro hry, rendering i profesionální výpočty přinášejí grafické karty GeForce RTX 50 Series a profesionální modely NVIDIA.