



Grafická karta je jednou z nejsložitějších hardwarových součástí počítače. Na první pohled vypadá jako pouhý kovový blok s ventilátory a čipem, ale uvnitř probíhá přesně řízený proces práce s daty. Paměť VRAM (Video RAM) sice uchovává obrovské množství informací pro hry, modely nebo videa, ale její rychlost nestačí na zásobování tisíců paralelních výpočetních jader. Proto GPU používá řadu rychlých vyrovnávacích pamětí, registrů a vyhrazených paměťových vrstev, které dohromady tvoří interní paměť GPU– důležitou spojnici mezi jádrem a hlavní pamětí VRAM.
V předchozím článku jsme se zabývali samotnou pamětí VRAM – typy pamětí, jako jsou GDDR, HBM nebo LPDDR. Tentokrát se však podíváme hlouběji – přímo do jádra GPU, které rozhoduje o tom, jak rychle dokáže karta zpracovávat data, vykreslovat obraz nebo počítat tisíce paralelních operací. A právě interní paměť GPU zde hraje hlavní roli.
VRAM versus interní paměť GPU – dva světy jedné grafiky
VRAM, videopaměť grafické karty, je externí součástí samotného čipu GPU. Uchovává velké množství dat – textury, modely, vyrovnávací paměť snímků nebo shaderové programy. Je to rychlá paměť, ale vzhledem k tomu, že se nachází mimo jádro, má vyšší latenci než interní paměť grafické karty. Data se přenášejí po paměťové sběrnici (např. 256bitové nebo 384bitové atd.), jejíž šířka a frekvence určují propustnost.
Moderní paměti jako GDDR6X nebo GDDR7 sice dosahují závratných rychlostí, ale GPU by byl neefektivní, kdyby musel neustále sahat po datech z VRAM. Proto jsou uvnitř čipu zabudovány menší, ale mnohem rychlejší paměti, které slouží jako prodloužená ruka výpočetních jader. Tyto komponenty společně tvoří interní paměť GPU, která funguje jako inteligentní mezičlánek mezi jádrem a pamětí VRAM.
Jak funguje architektura paměti GPU
Paměťová architektura grafické karty funguje jako dokonale organizovaná továrna, kde má každý prvek přesně danou úlohu. VRAM je obrovský sklad – obsahuje všechny textury, data, instrukce a modely, které GPU potřebuje k výpočtům. Paměti cache fungují jako distribuční regály, které připravují data k okamžitému použití, zatímco registry jsou skuteční „dělníci“, kteří s nimi přímo pracují. Dohromady tvoří komplexní síť, v níž se informace pohybují v přesně definovaných cyklech a rychlostních úrovních.
Každá výpočetní jednotka GPU – ať už se jedná o streamovací multiprocesor (SM) v architektuře NVIDIA, nebo výpočetní jednot ku (CU) v architektuře AMD – má svou vlastní vyrovnávací paměť L1 a registry. Tyto jednotky paralelně zpracovávají stovky až tisíce vláken, přičemž každé vlákno potřebuje okamžitý přístup ke svým datům. Aby nedocházelo ke zpomalení, GPU neustále přesouvá data mezi mezipamětí, registry a pamětí VRAM tak, aby byla vždy ve správný čas na správném místě. Tento proces řídí paměťový řadič, který rozhoduje, kdy a kam informace přenést.
Cílem celé architektury je zkrátit vzdálenost, kterou musí informace urazit. Přístup k paměti VRAM má totiž řádově vyšší latenci než interní paměť na čipu. Proto GPU ukládá nejdůležitější data co nejblíže výpočetním jádrům – do mezipaměti nebo registrů. Tím se minimalizuje latence a maximalizuje počet operací, které může karta zpracovat v jednom taktu.
Takto navržený systém pracuje v nepřetržitém cyklu: instrukce → načtení dat → výpočet → uložení výsledku → aktualizace cache. Díky tomu mohou moderní čipy zpracovávat miliardy instrukcí za sekundu, přičemž o plynulý tok informací se stará interní paměť GPU, která slouží jako rychlý most mezi jádrem a hlavní pamětí VRAM.

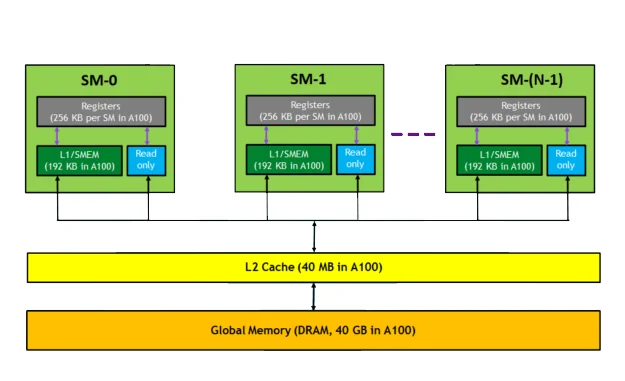
Paměť cache – mozek paměťové architektury GPU
Vrstvy cache jsou páteří systému, kterou představuje vnitřní paměť GPU. Ty zajišťují, že výpočetní jádra mají okamžitý přístup k datům, která nejčastěji potřebují. V grafickém čipu existuje více úrovní mezipaměti, od menších a rychlejších až po větší, které slouží jako mezivrstva mezi jádrem a pamětí VRAM. Jejich úkolem je udržovat data v neustálém pohybu, aby GPU nečekal ani jeden takt.
- Mezipaměti L1 se nacházejí u výpočetních bloků – například u shader jednotek v architekturách AMD nebo u streamovacích multiprocesorů (SM) v čipech NVIDIA. Ukládá se do ní malé množství dat, která se v daném okamžiku zpracovávají. Přístupová doba je extrémně krátká – řádově několik hodinových cyklů.
- Mezipaměť L2 je větší a sdílí ji více bloků. Slouží jako centrální odkládací zóna, kam se ukládají výsledky výpočtů, k nimž přistupují různé části GPU. Spolu s nižšími úrovněmi mezipaměti tvoří základ systému, který je interní pamětí GPU a zajišťuje rychlou komunikaci mezi jádrem a pamětí VRAM.
- Infinity Cache představuje nejvyšší úroveň mezipaměti v architekturách AMD. Není to klasická mezipaměť L3, ale funguje podobně – jako velká mezivrstva, která zvyšuje efektivní propustnost paměťového systému.
Architektura 2025 RDNA 4 využívá třetí generaci mezipaměti Infinity Caches kapacitou až 64 MB (v závislosti na modelu) a vylepšeným propojením s mezipamětí L2, což zvyšuje efektivní propustnost a snižuje zatížení paměti VRAM. Společnost NVIDIA se řídí stejným principem – generace Ada Lovelace nabízí až 96 MB vyrovnávací paměti L2 v čipu AD102, zatímco novější architektura Blackwell ji rozšiřuje až na 128 MB. V obou případech se jedná o maximální kapacity, které se mohou lišit v závislosti na konkrétním modelu, ale cíl zůstává stejný – zrychlit tok dat mezi jádrem a paměťovým systémem a zvýšit efektivitu, kterou poskytuje vnitřní paměť GPU.
Registry a paměť SRAM – rychlost přímo v jádře GPU
Jestliže mezipaměti jsou mozkem grafické karty, registry jsou jejími reflexy. Nacházejí se přímo ve výpočetních jednotkách a ukládají hodnoty, se kterými GPU právě pracuje – například data při výpočtu světla, stínů nebo pohybu. Jejich okamžitá odezva a vysoká rychlost patří mezi hlavní důvody, proč je interní paměť GPU schopna zpracovávat obrovské množství dat bez zpoždění.
Každé jádro má vlastní sadu registrů. Architektura NVIDIA Ada Lovelace jich má až 65 536 na jeden multiprocesor a jsou dynamicky rozdělovány mezi vlákna podle výpočetních potřeb. Podobný princip využívá i AMD RDNA 4, kde jsou registry optimalizovány pro zpracování instrukcí wave32 a wave64. V kombinaci s vrstvami cache zajišťují maximální rychlost výpočtů a plynulý chod celého GPU.
Speciální typy paměti v rámci GPU
Kromě klasických vrstev cache a registrů používají některé GPU speciální řešení. V mobilních GPU, jako je řada Apple A, čipy ARM Mali nebo Qualcomm Adreno, se používá architektura TBDR (Tile-Based Deferred Rendering). GPU zpracovává obraz v menších blocích – tzv. dlaždicích – které ukládá do lokální paměti dlaždic. Tento přístup výrazně zvyšuje efektivitu a přispívá k tomu, že interní paměť GPU může pracovat efektivněji a s nižší spotřebou energie.
V integrovaných grafických řešeních, jako jsou APU AMD, Intel Arc Xe, Iris Xe nebo Apple řady M, se zase používá sdílená systémová paměť. Jedná se o sdílený prostor pro CPU i GPU, který umožňuje přímý přístup k datům bez nutnosti jejich kopírování. Tento přístup sice šetří energii a zjednodušuje architekturu, ale nedosahuje výkonu, který nabízí vyhrazená interní paměť GPU.
Závěr
Moderní grafické karty již dávno nestaví pouze na kapacitě VRAM. Jejich skutečný výkon určuje také architektura interní paměti, která díky řešením, jež kombinuje interní paměť GPU, určuje rychlost zpracování i celkovou efektivitu čipu. Vývoj směřuje k optimalizaci propustnosti a inteligentní správě dat, což umožňuje dnešním GPU dosahovat vyššího výkonu při nižší spotřebě. Právě tato rovnováha mezi rychlostí, propustností a efektivitou bude určovat směr, kterým se budou ubírat budoucí generace grafických karet.